CP2K Standard Benchmarks on LUMI
The CP2K program contains a set of standard benchmarks, which are distributed with code. You can find them in the benchmarks/ directory in the source code folder. On the CP2K, you can find some data for other HPC clusters on the performance page.
Preliminary LUMI-G Benchmarks (Feb. 2023)
These were run in the beginning of 2023 with the CP2K 2023.1 release version compiled according to the instructions published in the howto section. On LUMI-C, no special core binding was used except what is provided by SLURM using e.g. #SBATCH -c 8 for MPI + OpenMP jobs.
Summary
| Benchmark | Nodes | LUMI-C | LUMI-G | Speed-up |
|---|---|---|---|---|
| H2O-256 | 1 | 6.6 s | 14.2s | 0.46x |
| H2O-512 | 4 | 11.0 s | 21.0s | 0.52x |
| H2O-1024 | 8 | 35.2 s | 58.5s | 0.60x |
| QS_DM_LS | 4 | 723 s | 436 s | 1.65x |
| H2O-64-RI-dRPA-TZ | 8 | 298 s | 194 s | 1.5x |
| H2O-128-RI-dRPA-TZ | 32 | 1065 s | 285 s | 3.7x |
DFT Molecular Dynamics (QS/H2O-x)
These benchmark runs ab initio molecular dynamics (MD) with DFT, on a varying number of water molecules (from 32 to 8192) with TZV2P basis and plane-wave cutoff of 280 Ry. On LUMI-C,
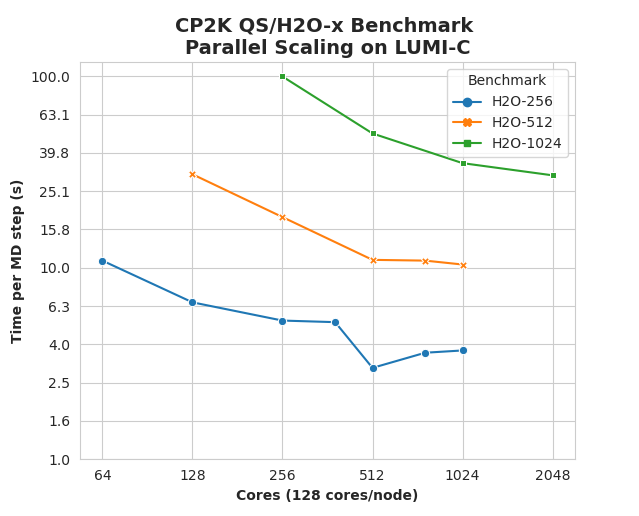
The data points are the wall-time taken per MD steps (i.e. one fully converged SCF cycle, typically only a few SCF steps in MD simulations). On LUMI-C, it is possible to run huge cell with a relatively small number of compute nodes. The parallel scaling is decent, but could be better, when comparing to e.g. these benchmarks from Cray XC30 Archer in 2013. It is possible that it related to the network issues seen on LUMI at the start, which still persist.
For smaller jobs (1-4 compute nodes), using 64 MPI ranks per node and OMP_NUM_THREADS=2 is the best, but for larger jobs (8+ nodes) running with 32 ranks per node and OMP_NUM_THREADS=8 tends to be faster.
But can these be run on GPUs in the LUMI-G partition? The table below compared the time per MD step when running on LUMI-G nodes (8 GPUs/56 cores) vs LUMI-C nodes (128 cores):
| Benchmark | Nodes | LUMI-C | LUMI-G | Speed-up |
|---|---|---|---|---|
| H2O-256 | 1 | 6.6 s | 14.2s | 0.46x |
| H2O-512 | 4 | 11.0 s | 21.0s | 0.52x |
| H2O-1024 | 8 | 35.2 s | 58.5s | 0.60x |
It turns out the that GPU acceleration on LUMI is not that effective for regular DFT calculations. The time taken per MD step is almost twice that of LUMI-C node when comparing 1 LUMI-G node vs 1 LUMI-C node. The results are somewhat disappointing, but a check in the output confirms that many operations are not GPU-accelerated, e.g.
-------------------------------------------------------------------------------
- -
- DBCSR STATISTICS -
- -
-------------------------------------------------------------------------------
COUNTER TOTAL BLAS SMM ACC
flops 9 x 9 x 32 3698882869248 0.0% 100.0% 0.0%
flops 32 x 32 x 32 3807488507904 0.0% 0.0% 100.0%
flops 22 x 9 x 32 5135416602624 0.0% 100.0% 0.0%
flops 9 x 22 x 32 5151420223488 0.0% 100.0% 0.0%
flops 22 x 22 x 32 7121164328960 0.0% 100.0% 0.0%
flops 32 x 32 x 9 10427106852864 0.0% 100.0% 0.0%
flops 32 x 32 x 22 12744241709056 0.0% 100.0% 0.0%
flops 9 x 32 x 32 12749107101696 0.0% 100.0% 0.0%
flops 22 x 32 x 32 15582242013184 0.0% 100.0% 0.0%
flops 9 x 32 x 9 30219541585920 0.0% 100.0% 0.0%
flops 22 x 32 x 9 39766190137344 0.0% 100.0% 0.0%
flops 9 x 32 x 22 39766190137344 0.0% 100.0% 0.0%
flops 22 x 32 x 22 52085304426496 0.0% 100.0% 0.0%
flops inhomo. stacks 0 0.0% 0.0% 0.0%
flops total 238.254296E+12 0.0% 98.4% 1.6%
flops max/rank 29.798089E+12 0.0% 98.4% 1.6%
matmuls inhomo. stacks 0 0.0% 0.0% 0.0%
matmuls total 17486460992 0.0% 99.7% 0.3%
number of processed stacks 2865104 0.0% 86.1% 13.9%
average stack size 0.0 7061.9 146.3
marketing flops 375.300685E+12
-------------------------------------------------------------------------------
Only a subset of operations (32x32x32) are running on the GPU (100% in the ACC column). It then makes sense that the runtime is doubled with half the number of CPU core per node.
Linear Scaling DFT (QS_DM_LS)
What about linear scaling DFT? Does it work better on the GPU nodes. Using the previous benchmarks (see below) as a baseline, I get the following using 8 MPI ranks/8 GPUs per LUMI-G node and OMP_NUM_THREADS=7 to account for only 63 available cores.
| Nodes | LUMI-C | LUMI-G | Speed-up |
|---|---|---|---|
| 4 | 723 s | 436 s | 1.65x |
| 8 | 462 s | 278 s | 1.65x |
In this case, there is some speed-up, even if it is not dramatic. The ratio of GPU-node to CPU-node speed seems to be somewhat better (1.6x vs 1.3x) compared to what was observed on Piz Daint with GPU acceleration (this page). The output file confirms much more GPU usage, for example in the DBCSR library:
-------------------------------------------------------------------------------
- -
- DBCSR STATISTICS -
- -
-------------------------------------------------------------------------------
COUNTER TOTAL BLAS SMM ACC
flops 23 x 23 x 23 2229574562881438 0.0% 0.0% 100.0%
flops inhomo. stacks 0 0.0% 0.0% 0.0%
flops total 2.229575E+15 0.0% 0.0% 100.0%
flops max/rank 79.250686E+12 0.0% 0.0% 100.0%
matmuls inhomo. stacks 0 0.0% 0.0% 0.0%
matmuls total 91623841657 0.0% 0.0% 100.0%
number of processed stacks 3127188 0.0% 0.0% 100.0%
average stack size 0.0 0.0 29299.1
marketing flops 891.964171E+15
-------------------------------------------------------------------------------
It is doubtful, though, if it makes economic sense to run these kind of calculations on LUMI-G, as you would typically need to see a speed-up of at least 3x to 4x for it to make sense.
An interesting find is that activating huge memory pages (2 MB) significantly speeds up the GPU version of the code (but not so much the CPU-only version). For example, the original timing for the 4 LUMI-G node run was ca 540 s without huge pages, compared to 436 s when the binary is linked with the craype-hugepages2M module. It is about 25% faster. Increasing the huge page size further to 8 MB did not result in any more improvement.
RPA Calculations (QS_mp2_rpa)
The benchmarks in his folder run single-point energy calculations using MP2 and RPA with RI approximation. These are heavy calculations, typically 100x more expensive then regular DFT.
For the medium 64-H2O benchmark with (192 atoms) I get these timings with RPA energy activated (H2O-64-RI-dRPA-TZ.inp):
| Nodes | LUMI-C | LUMI-G | Speed-up |
|---|---|---|---|
| 8 | 298 s | 194 s | 1.5x |
| 16 | 186 s | 115 s | 1.6x |
The RPA module reports ca 1.3 TF/s of floating point performance per MPI rank, compared to around 0.1 TF/s rank with CPUs only (16 ranks per node with OMP 8), which shows some significant GPU usage, but far from the peak performance which is theoretically up to 24 TF/s per GCD. There is again some speed-up with the GPU nodes, but not enough for it make sense to run these calculations on LUMI-G.
But there is also a larger RPA benchmark with 128 water molecules (H2O-128-RI-dRPA-TZ.inp). This benchmark was used as part of the performance benchmarks used in the procurement of LUMI. The committed value at delivery by HPE was 188 s using 128 LUMI-G nodes, which was met with some margin during testing. I only ran up to 32 GPU nodes in my own testing, but got similar, or better results even using rather conservative extrapolation up to 128 nodes (1.5x speed with 2x compute nodes):
| Nodes | LUMI-C | LUMI-G | Speed-up |
|---|---|---|---|
| 16 | (OOM) | 525 s | |
| 32 | 1065 s | 285 s | 3.7x |
| 64 | ~190 s | ||
| 128 | ~127 s |
Here, we can see some promising speed-up. The RPA module reports 2.4 TF/s per MPI rank on the GPU nodes vs the 0.2 TF/s rank on the CPU nodes. It still not close to the GPU peak performance but enough to accelerate the calculations significantly. This larger RPA calculation makes sense to run on the GPU nodes.
LUMI-C benchmarks from Jan. 2022
These were run on LUMI-C during 2022 with CP2K 9.1 built from the LUMI EasyBuild recipes.
QS_DM_LS Linear scaling DFT
This benchmark using the linear scaling DFT method in CP2K and simulates 6912 water molecules (21k atoms) with DZVP basis and 300 Ry cut-off. It runs for 2 SCF iterations (which is not enough to achieve convergence).
I was able to ran some benchmarks with many nodes on LUMI-C during Jan 2022 with CP2K 9.1 and no extensive tuning other testing different values of OMP_NUM_THREADS, but the results were not impressive compared to what was published before for e.g. the Piz Daint and Noctua clusters on the CP2K web page:
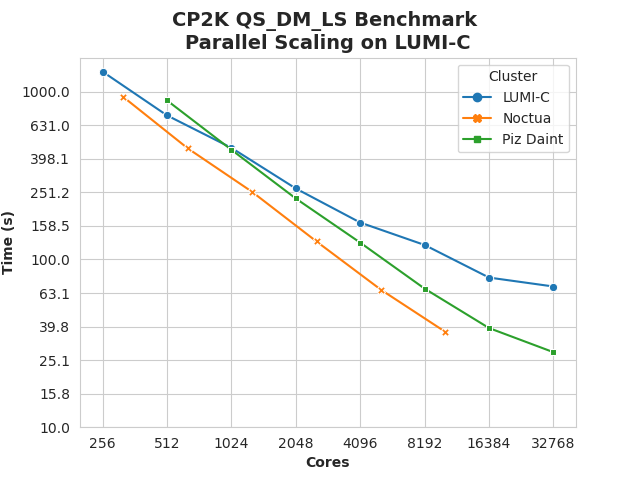
I was not able to scale out sufficiently to beat the fastest time to solution as run previously on e.g. the Piz Daint (the year 2015 configuration with Cray XC30 with Intel Xeon Sandy Bridge and 1 Nvidia Tesla GPU K20X per node?) and the Noctua clusters (Intel Xeon Skylake with 100 Gbit/s Omni-Path network). It seems to primarily be a network/scaling problem as the speed on low core counts (256-512) is still ok.
Running with 16 MPI ranks per compute node with 8 OpenMP threads (OMP_NUM_THREADS=8) was generally the fastest. I advise to always use at least OMP_NUM_THREADS=2 when running on LUMI-C, as empirically, loading 128 MPI ranks per node increases the risk of running into various network problems.